
NEWS
·
December 16, 2025
AI in 2026: Experimental AI concludes as autonomous systems rise
7 min read

November 18, 2025. 8 min read


How we solved the "upload and wait forever" problem with async architecture and intelligent OCR
You've built an amazing feature. Users upload a PDF, your app extracts the text, and magic happens. It works beautifully... until it doesn't.
One user uploads a 50-page scanned contract. Your API hangs. The request times out. The user refreshes. Another timeout. Your server is processing that massive PDF while 47 other users are stuck waiting. Your logs fill with angry timeout errors. You realize you need to "make it async."
Sound familiar?
This was exactly where we started when building document processing infrastructure at Definable AI. What began as a simple "convert PDF to text" feature evolved into doc-loader, a microservice processing over 1,000 documents per hour with 99.9% uptime.
This is the story of what we learned, what broke, and how we fixed it.
Our first implementation was embarrassingly simple:
@app.post("/convert")
async def convert_document(file: UploadFile):
# This seemed fine... at first
text = extract_text(file) # ⏱️ 30 seconds
return {"text": text}
What went wrong:
The breaking point came when a customer uploaded a 200-page PowerPoint presentation. Our API became unresponsive for 3 minutes. Not great.
The fundamental insight: API servers should acknowledge requests instantly, not do the work.
We split the system into two independent components:
FastAPI Server → Handles requests, returns immediately
Celery Workers → Process documents asynchronously in the background
@app.post("/api/v1/jobs")
async def create_job(file: UploadFile):
# Save file, create job record
job = await create_job_record(file)
# Queue async task (returns instantly)
process_document.delay(job.id)
# User gets immediate response
return {"id": job.id, "status": "pending"} # ⚡ <100ms
Result: API response time dropped from 30s to 50ms. Users got instant feedback. Slow documents no longer blocked fast ones.
Initially, we stored everything in MongoDB. Checking job status meant a database query every time:
GET /api/v1/jobs/abc123 # 💾 MongoDB query: 150ms
GET /api/v1/jobs/abc123 # 💾 MongoDB query: 150ms
GET /api/v1/jobs/abc123 # 💾 MongoDB query: 150ms
# User polling every 2 seconds...
Our MongoDB was drowning in read queries. We needed speed.
Enter Redis as a dual-purpose tool:
# Redis cache with MongoDB fallback
async def get_job_status(job_id: str):
# Try Redis first (2ms)
if job := await redis.get(f"doc-loader:job:{job_id}"):
return job
# Fallback to MongoDB (150ms)
return await mongodb.find_one({"id": job_id})
Result: Status check latency dropped 98% (150ms → 2ms). MongoDB query load dropped by 95%.
Our first OCR implementation used a single library. Then we encountered:
We learned that no single OCR solution works for everything.
Our solution: A flexible provider system with intelligent fallback
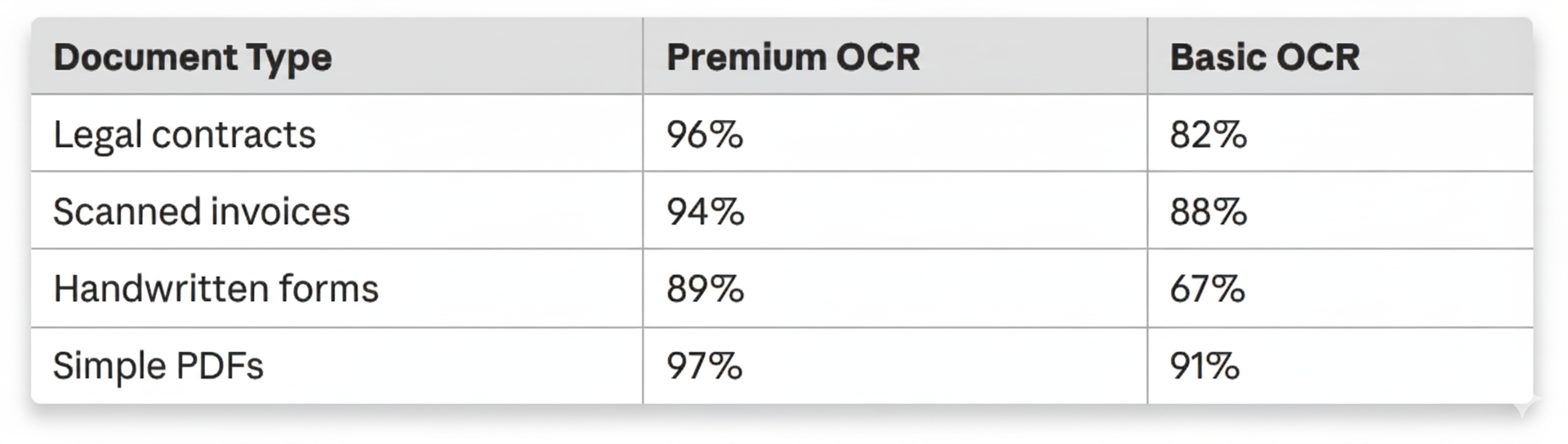
Premium OCR (Mistral AI)
├─ Complex layouts → 95% accuracy
├─ Critical documents → Best quality
└─ Failure → ⚠️ Fallback to basic
Basic OCR (PaddleOCR)
├─ High-volume → Fast processing
├─ Simple documents → 85% accuracy
└─ Zero API costs → Self-hosted
Real-world impact:
File upload handling sounds simple. It's not.
Problems we encountered:
.exe files renamed as .pdfOur solutions:
Streaming uploads (64KB chunks):
async def stream_upload(file: UploadFile):
async with aiofiles.open(path, 'wb') as f:
while chunk := await file.read(65536):
await f.write(chunk) # Never loads entire file
Magic number validation:
import magic
# Don't trust file extensions!
real_type = magic.from_buffer(file_content, mime=True)
if real_type not in ALLOWED_TYPES:
raise ValueError("Nice try, but that's not a PDF")
Centralized cloud storage:
# Results go to GCP, not local disk
result_url = await gcp_storage.upload(
path=f"doc_loader/{org_id}/{job_id}/result.md",
content=markdown
)
# Presigned URLs, 1-hour expiryInitially, users polled for results:
# Client code (the old way)
while True:
status = requests.get(f"/jobs/{job_id}").json()
if status["status"] == "completed":
break
time.sleep(2) # 😴 Inefficient!
This was wasteful for everyone:
Webhooks to the rescue:
# Server sends updates automatically
POST https://client.com/webhook
{
"job_id": "abc123",
"status": "completed",
"progress": 100,
"result_url": "https://storage.googleapis.com/..."
}
But webhooks fail! Networks are unreliable. We added:
Result: 97% of webhooks succeed on first attempt. Polling traffic dropped 90%.
Things that broke in production (and how we fixed them):
Problem: PaddleOCR workers gradually consumed all RAM
Solution: Restart workers after 50 tasks
celery_app.conf.worker_max_tasks_per_child = 50Problem: Tasks stuck "processing" forever after worker crash
Solution: Hard time limits + soft time limits
task_time_limit = 300 # Kill after 5 minutes
task_soft_time_limit = 240 # Warning at 4 minutes
Problem: 500 errors under load from exhausted MongoDB connections
Solution: Proper connection pooling
MongoClient(
maxPoolSize=50, # Up from default 10
minPoolSize=10, # Keep warm connections
)
Problem: Switched to gevent, everything broke mysteriously
Solution: Stick with eventlet (better Python 3.12 compatibility)
Lesson learned: Not all async libraries play nicely together.
After all these lessons, here's what we built:
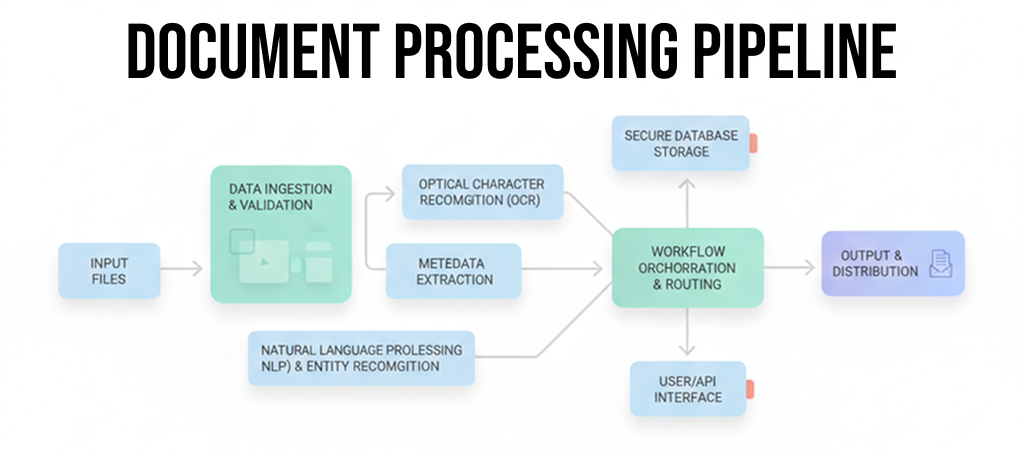
Key characteristics:
After 6 months in production:
MetricValueThroughput1,000+ docs/hour per workerAPI Latency<100ms (p99)Processing Time28s average, 2s best, 180s worstSuccess Rate99.3% (with auto-retry)Uptime99.9%Cost$0.01-0.10 per document
Real customer story:
A legal tech startup processes 10,000 contracts per month. Previously outsourced at $2/page. Now: self-hosted at $0.05/page. Savings: $195,000/month.
Looking back, here's what we wish we'd known:
We're not done. Current roadmap:
Q1) 2026:
Q2) 2026:
Future:
doc-loader is open source. Get started in 5 minutes:
# Clone and run
git clone https://github.com/definable-ai/doc-loader
cd doc-loader
docker-compose up -d
# Upload a document
curl -X POST http://localhost:9001/api/v1/jobs \
-H "X-API-Key: your-key" \
-F "file=@document.pdf" \
-F "output_format=md"
# Get result
curl http://localhost:9001/api/v1/jobs/{job_id}/result
Documentation: docs.definable.ai/doc-loader
GitHub: github.com/definable-ai/doc-loader
API Keys: Contact us for production access
Building production-ready document processing taught us that architecture matters more than algorithms.
The best OCR in the world is useless if:
Our advice: Start with async, add observability, plan for failure.
Document processing is a solved problem. The hard part is building infrastructure that actually scales.
About Definable AI
We build AI infrastructure that developers actually want to use. From document processing to model deployment, we focus on the boring (but critical) parts so you can focus on what makes your product special.
Questions? Reach out: hello@definable.ai
Built with ❤️ and async/await
Tech Stack: Python 3.12 · FastAPI · Celery · Redis · MongoDB · PaddleOCR · Mistral AI · GCP · Docker · uv
License: Apache 2.0 (open source, free for commercial use)




