How to build great tools for AI agents: A field guide
Definable AI · October 27, 2025 · 12 min read
Make AI agents reliable with precise tool metadata, narrow-scope tools, and strict parameter schemas. Practical field guide with concrete design rules.
Key Takeaways
- Explicit, unambiguous tool metadata and constraints significantly improve agent reliability and can eliminate recurring failures.
- Adopt consistent naming (prefer snake_case) and design each tool to perform a single, atomic action.
- Keep descriptions short and actionable using an 'action + context' template and state only high-impact limits.
- Define parameters with strong types, enums, explicit formats, and minimal top-level fields, then monitor and iterate with tests.
The critical insight gleaned from the Firecrawl tool failure was the pivotal importance of explicit and precise tool metadata (descriptions, names, and request schemas) for successful agent operation. Despite the function working perfectly in isolation, the autonomous agent consistently failed because the original schema didn't explicitly state the dependency: "If format is json, jsonOptions is required." By adding this specific, non-ambiguous constraint, the failure rate dropped to zero. This experience demonstrated that optimizing tool interfaces—by making requirements completely unambiguous and drawing lessons from industry leaders—is a high-leverage activity that dramatically improves agent reliability, unlocks significant value, and boosts overall platform performance for users.
TL;DR
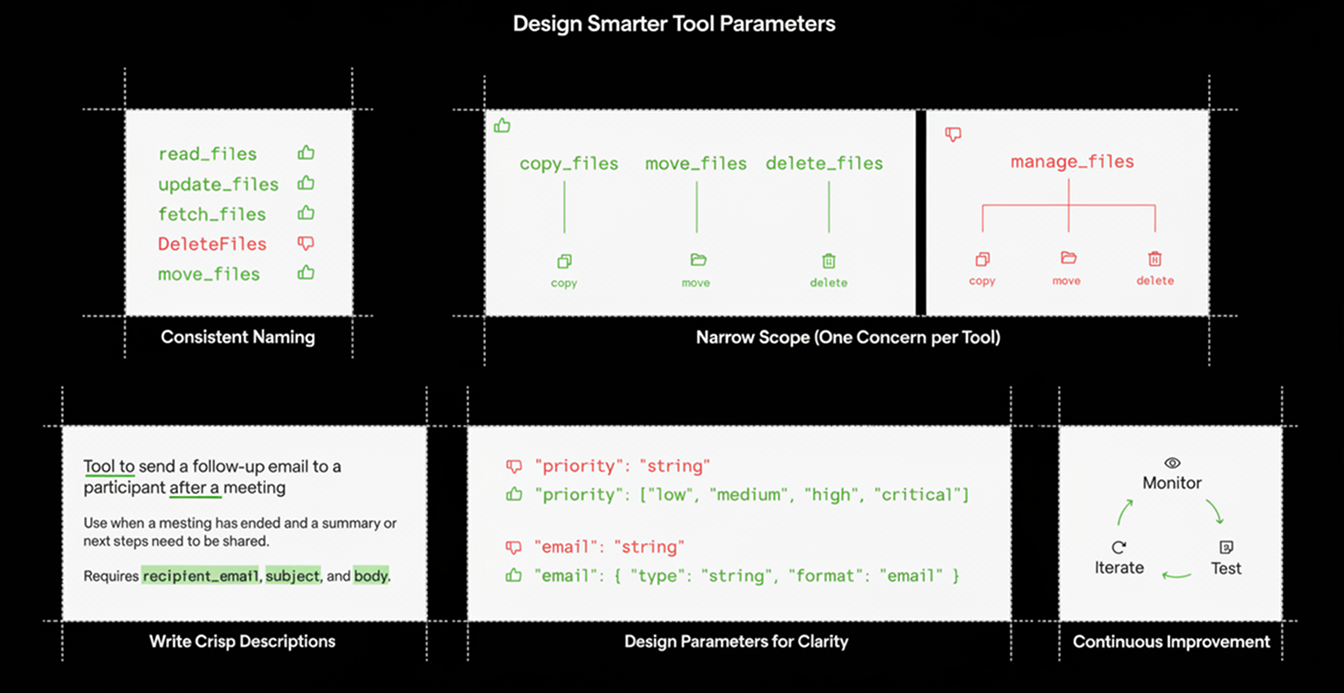
- Consistent Naming
- Stick to one style,
snake_casepreferred. - Inconsistent names confuse LLMs and lower invocation accuracy.
- Stick to one style,
- Narrow Scope (One Concern per Tool)
- Each tool = one atomic action.
- Split large “do-everything” tools into smaller, precise ones.
- Write Crisp Descriptions
- Template: “Tool to
. Use when .” - State critical constraints up-front (“after confirming …”).
- List impactful limits only (e.g., “max 750 lines”).
- Keep it short—under 1024 characters.
- Template: “Tool to
- Design Parameters for Clarity
- Document hidden rules (“At least one of agent_id | user_id | run_id | app_id is required”).
- Strong typing everywhere; use enums for finite sets.
- Fewer top-level params → fewer model mistakes.
- Declare formats (
"format": "email", dates, etc.). - Embed tiny examples right inside the description.
- Continuous Improvement
- Monitor anonymised production errors to identify friction points.
- Add automated tests & evals before every change—know if you helped or hurt.
- Iterate relentlessly; tooling is never “done.”
Fundamental Principles for Building Great Agent Tools
Developing effective agent tools requires more than guesswork or intuition. Through our research—drawing on insights from OpenAI, Google Gemini, Anthropic Claude, and hands-on exploration of agents like Cursor and Replit—we’ve identified a set of fundamental principles. Below are two core tenets that deserve close attention.
i. Why Consistent Formatting Matters
A simple but highly effective design principle for tool collections is to use consistent naming conventions. We follow a snake_case standard for all tools, since variations in naming can confuse models—sometimes making them assume one tool is better or different than another—resulting in unpredictable performance and longer debugging sessions.
ii. What is the Narrow Scope Principle: One Concern Per Tool
1. Polished and professional:
Another key principle we’ve discovered is the importance of maintaining a narrow, well-defined scope for each agent tool. Every tool should ideally handle a single, specific, and atomic operation. Although minimizing complexity may initially seem counterintuitive—since a narrower scope can lead to more individual tools—our observations, including those from leading systems like Cursor and Replit, consistently show that atomic, single-purpose tools reduce ambiguity, simplify debugging, and improve long-term maintainability.
For instance, a broadly defined tool such as manage_files, capable of copying, moving, deleting, or renaming files through conditional arguments, often introduces unnecessary complexity. This design increases the likelihood of errors and makes it harder for AI models to use the tool correctly. By contrast, separating these actions into distinct tools—like copy_file, move_file, and delete_file—creates clearer boundaries and leads to more reliable, low-friction interactions.
Writing Perfect Tool Descriptions
Even if your agent tools are solidly built, their effectiveness can be undermined by vague, overly complex, or unclear descriptions.
Your goal with every description is simple yet critical:
- Clearly convey what the tool does.
- Precisely indicate when the AI should invoke it.
To achieve this balance quickly and effectively, we recommend a straightforward, proven template:
This simple structure clarifies two critical dimensions right away: action and context. That improved clarity leads directly to fewer invocation errors from your agent.
When and How to State Constraints:
Explicit constraints are critical hints for the AI, guiding it toward optimal tool invocation while preventing incorrect actions. Google's Vertex AI documentation illustrates this neatly; their sample function description explicitly calls out required user inputs as preconditions:
- "Book flight tickets after confirming the user's requirements (time, departure, destination, party size, airline, etc.).”
This addition isn't just informative but an implicit directive instructing the AI clearly about when this tool is appropriate, significantly reducing errors.
Other explicit constraints examples might look like:
- Translation: “Translates text from one language to another. Use only if the user specifically asks for translation.”
Accurately Communicate Limitations (but Selectively):
Be honest and transparent about tool limitations, but do so sparingly and intentionally. Cursor’s internal tools, for instance, transparently inform users if there's a specific handling limitation directly within the description:
- “Read File – Read the contents of a file (up to 750 lines in Max mode).”
This kind of targeted limitation transparency is crucial because it ensures the agent never exceeds realistic capabilities, minimizing avoidable invocation errors.
But be cautious: don't clutter all your tool descriptions with every conceivable limit or minor constraint. Reserve limitations for genuinely impactful constraints —those that could significantly affect the tool’s correctness or reliability, such as hard data input caps, API key requirements, or format restrictions.
Remember, your AI model can't peek into the code behind the tool, and it depends entirely on what your description says. Ensure accuracy, be transparent, and review and update frequently.
Description Length: The Sweet Spot
Precision doesn't require lengthy prose. Shorter, well-crafted descriptions typically perform best. Long, verbose descriptions may dilute critical details and occupy limited prompt context space unnecessarily. Indeed, platforms like OpenAI impose a practical limit—specifically, OpenAI sets a 1024-character cap on function descriptions.
The Art of Defining Tool Parameters
A tool’s effectiveness often depends less on its description and more on how its input parameters are defined. Clear, well-typed parameters with explicit constraints and meaningful enums significantly reduce model errors. Our testing confirms that this design discipline leads to measurable performance gains.
Core Guidelines for Great Parameter Design
To help AI agents consistently succeed at invoking tools, strive to follow these essential guidelines in parameter design:
i. Explicitly Document All Parameter Nuances
When defining parameter descriptions, never leave important usage nuances implied or unclear. Consider, for instance, the AddNewMemoryRecords function from mem0’s API. In this case, while parameters like agent_id, run_id, user_id, and app_id are individually optional, the function logic requires at least one to be provided. Explicitly stating this nuance in parameter descriptions saves your AI agent (and its developers!) from unnecessary confusion:
Doing this creates crystal-clear usage guidelines, making successful tool invocation dramatically easier.
ii. Always Use Strongly Typed Parameters (Prefer Explicit Types):
Clearly defined and strongly-typed parameters help the agent quickly discern intended data types, minimizing invocation errors. If a parameter accepts finite categorical values, define them explicitly as enums, instead of leaving them ambiguous within the description.
Anthropic and OpenAI both support enum in schemas, and the Vertex AI documentation explicitly says to use an enum field for finite sets rather than expecting the model to read options from text. This has two benefits: it constrains the model’s output (reducing the chance of typos or unsupported values), and it teaches the model the expected domain of that parameter in a machine-readable way.
Replace something like this vague definition:
With a strongly defined enum-based schema:
This change noticeably reduces confusion and incorrect parameter values.
iii. Keep Parameters to a Minimum Whenever Possible:
Google’s Agent Toolkit emphasizes a critical point—fewer parameters are generally better. Complex parameter lists significantly increase the likelihood of accidental misplacements and mistakes by your agent.
If you feel that the function requires an extensive list of parameters, consider breaking it down into smaller functions. We are experimenting with adding objects instead of primitive types, but the general consensus is that primitive types like str and integer work better than objects.
iv. Use Explicit Formatting and Constraints:
When parameters expect specialized string formats—like emails, dates, or IP addresses—always explicitly define these through the format keyword in your JSON schema.
For instance, instead of the vague definition:
Always prefer explicit format annotations:
Note that Pydantic models don’t natively enforce the format constraint. In Python projects using Pydantic, you can incorporate JSON Schema formatting through modern techniques compatible with current Pydantic versions.
This ensures type and format constraints remain rigorously enforced and transparent to the agent.
v. Add Short, Immediate Examples Within the Parameter Description Itself:
While schema definition often includes a dedicated examples area, always reinforce clarity by adding brief examples directly within parameter descriptions themselves (when helpful). This especially helps in cases where the parameter has to follow a specific format. For example, the list threads function in Gmail has examples for the format in which the queries should be defined:
Immediate examples further reinforce the agents' understanding, paving the way for improved accuracy.
Continuous Improvement through Tool Monitoring & Refinement
Agent tooling is never a static, set-and-forget process. Tools operate within a dynamic ecosystem where model architectures evolve, user expectations shift, and real-world conditions often deviate from early assumptions. To maintain reliability and precision, continuous monitoring and iterative refinement are not optional—they’re essential.
We observed nearly a 10× reduction in tool failures after applying the principles outlined in this post.
At Definable, we rigorously track anonymized production errors from agent tool calls. Every error provides valuable insights into what went wrong—whether it’s confusion in invocation logic, unclear parameter definitions, or hidden constraints that weren’t properly surfaced. By analyzing these patterns, we can methodically identify and address the root causes of failure.
In parallel, we’re investing heavily in automated testing and evaluation frameworks for our agent tools. Without concrete testing, it’s impossible to know whether new changes enhance performance or introduce regressions. Robust automated testing acts as a safeguard, giving our team confidence to iterate rapidly while maintaining reliability.
We’ll be sharing more about our approach to evaluating tool quality in an upcoming post—stay tuned.
Conclusion: Elevating AI Agent Tooling
Building exceptional tools for AI agents isn’t a casual task—it’s a disciplined engineering effort rooted in clear standards, intentional design, and continuous iteration. From consistent naming and precise scoping to concise descriptions and well-defined parameters, every detail plays a critical role. Behind every capable AI agent—whether it’s Cursor improving developer productivity or Claude Code powering intelligent automation—lies an immense amount of invisible craftsmanship, careful planning, and precisely engineered tooling. At Definable, we’ve spent countless hours studying the best practices of platforms like Google, OpenAI, and Anthropic, refining and challenging those ideas in real-world applications. We’re deeply committed to building high-quality tooling, because it forms the backbone of truly effective AI agents. In future posts, we’ll share more about how we test, measure, and improve our tools. We hope the principles and frameworks outlined here help you in your own journey toward creating exceptional agent ecosystems. There’s much more to come—stay tuned.
Frequently Asked Questions
Why is precise tool metadata important for AI agents?
Agents rely on names, descriptions, and request schemas to decide when and how to call tools; explicit metadata and constraints drastically reduce invocation errors.
How should I name and scope my agent tools?
Use a consistent naming convention (snake_case recommended) and follow a single-responsibility rule: one atomic action per tool to minimize ambiguity and errors.
What are best practices for defining tool parameters?
Use strong typing, enums for finite sets, explicit formats (email, date), document hidden rules, and keep top-level parameters minimal to lower model mistakes.
How do I validate and improve tools in production?
Monitor anonymized error logs, run automated tests and evals before changes, measure invocation accuracy, and iterate continuously to reduce friction.